This project involved researching Fisher’s famous Iris dataset and then writing documentation and code in the Python programming language based on that research.
 Iris Versicolor |
 Iris Virginica |
 Iris Setosa |
This was the second project completed for the Programming and Scipting module of the Higher Diploma in Computing and Data Analytics at GMIT which was the first programming module taken in the first semester of the course.
The aim of the project was to research the well-known Fisher’s Iris data set [1] and then writing documentation and code in the Python programming language based on that research.
The project repository is on GitHub. The project was to be completed using a source code editor such as Visual Studio Code rather than a notebook applicaton such as the Jupyter Notebook application. As per the project requirements, the project README contains an overview of the project, my research into the Iris dataset, visualisations of the Iris datasets generated by the Python scripts as well as some Python code snippets, detailed explanations and discussion as well as a list of all references used. The Python .py scripts written for the project are also included in the project repository.
This post is a summary and overview of the project repository. The aim of the project was to investigate the Iris dataset using the Python programming language. Python can be used to gain a high level overview of a dataset such as the Iris dataset. Statistics and visualisations can be very easily generated using a programming language such as Python. Plots produced in Python can provide an overview of of a dataset. The Python programming language is widely used in statistical and machine learning. The Iris data set is frequently referenced in online tutorials and text books relating to machine learning.
My main objective in this project was to learn more about the Python programming by applying it to the Iris data set in this project. There are many free resources available, starting with the extensive Python documentation for its standard library of modules. There are also several well known third-party packages that enhance the use of Python and are used for data analytics and machine learning.
A web search on the Iris data set will return many pages of results. Many of these apply machine learning to the Iris data set. I looked at the reasons why the Fisher Iris dataset is considered such an important database in the field of statistical and machine learning - particularly in the area of classification.
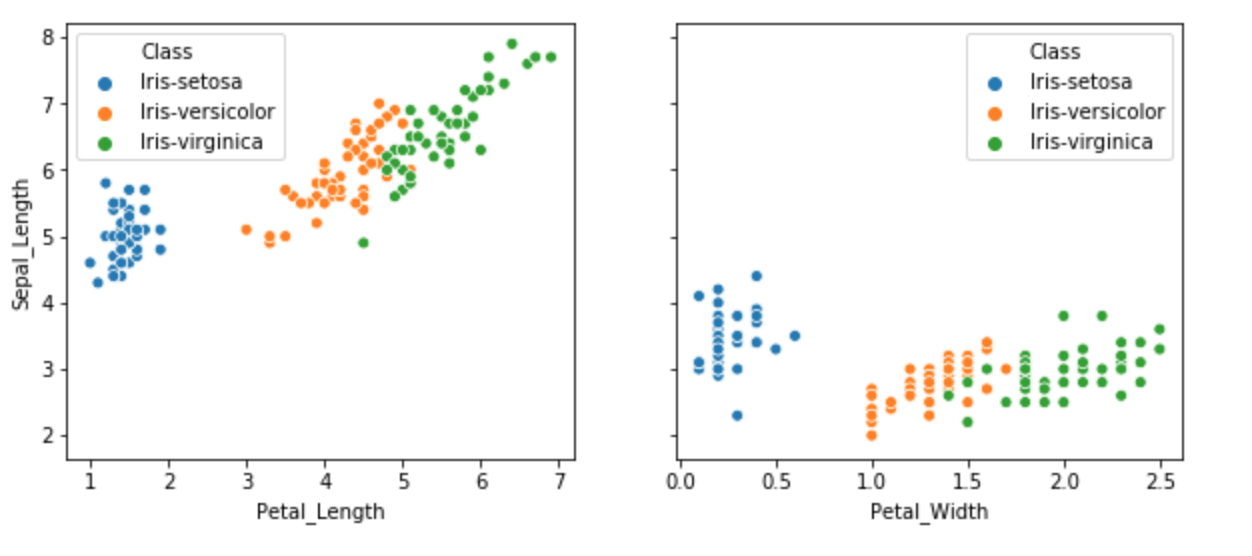
The Iris dataset is described as having one class that is linearly separable from the other two classes so I looked at this in the code, particularly through the use of some plots.
-
Researching the Fisher Iris Dataset. Some background to the Iris dataset available from the UCI Machine Learning Repository and how it came to be widely used in learning classification methods.
-
Python and other software tools used in project. About the Python code used and how to download and run the code for this project.
-
Importing and viewing the Iris dataset using
pandas. Thepandaslibrary is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. -
Investigating the Iris Dataset using Python. This section provided an overview of the Fisher Iris data set using
pandasincluding some summary statistics that describe the data at a high level and some basic visualisations (histograms, boxplots and scatterplots) usingMatplotlibandSeabornthat provide an overall picture of the Fisher Iris data set. -
Summary and Conclusions Much of modern statistical and machine learning is based upon the work of R.A Fisher in the 20th century and he is often referred to as the father of modern statistics. Fisher developed the linear discriminant model based on the combination of the four measurement features in the Iris dataset. The dataset became a test case for classification methods in the machine learning and the pattern recognition field because one class of the three Iris species in the data set is linearly separable from the other two classes while the other two classes are not linearly separable from each other.
-
References List of references used in this project.
[1] UC Irvine Machine Learning Repository. Iris data set. http://archive.ics.uci.edu/ml/datasets/Iris.